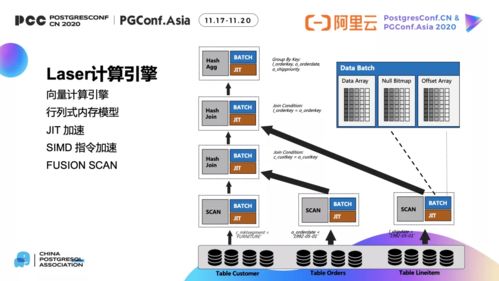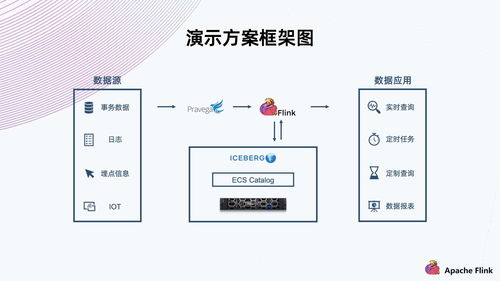
隨著大數(shù)據(jù)與云原生技術(shù)的深度融合,企業(yè)對于實時、高效、低成本的數(shù)據(jù)處理與存儲需求日益增長。傳統(tǒng)的數(shù)據(jù)倉庫架構(gòu)在面對海量、多源、頻繁更新的數(shù)據(jù)時,常顯露出性能瓶頸、管理復(fù)雜與存儲成本高昂等問題。在此背景下,結(jié)合Apache Flink的流批一體處理能力與Apache Iceberg的表格式抽象,并以對象存儲(如AWS S3、阿里云OSS、騰訊云COS等)為底層存儲,構(gòu)建現(xiàn)代化數(shù)據(jù)湖方案,已成為業(yè)界實現(xiàn)統(tǒng)一、可擴展、低成本數(shù)據(jù)處理與存儲服務(wù)的重要路徑。
一、 核心組件:強強聯(lián)合的技術(shù)棧
- Apache Flink:作為流批一體的計算引擎,F(xiàn)link提供了高吞吐、低延遲的數(shù)據(jù)處理能力,支持精確一次(Exactly-Once)語義,并能夠無縫處理有界(批)和無界(流)數(shù)據(jù)。其成熟的生態(tài)系統(tǒng)和豐富的連接器(Connector)使其成為數(shù)據(jù)入湖、湖內(nèi)ETL及數(shù)據(jù)服務(wù)層計算的理想選擇。
- Apache Iceberg:作為一種開源的表格式(Table Format),Iceberg在HDFS或?qū)ο蟠鎯χ咸峁┝艘粚痈咝У某橄蟆K鉀Q了Hive表格式在并發(fā)寫入、數(shù)據(jù)更新、模式演進(Schema Evolution)和時間旅行(Time Travel)等方面的諸多痛點。其核心特性包括:
- ACID事務(wù)支持:確保多任務(wù)并發(fā)讀寫時數(shù)據(jù)的一致性。
- 隱式分區(qū)與分區(qū)演進:解耦物理存儲與查詢邏輯,允許靈活修改分區(qū)策略。
- 高性能元數(shù)據(jù)管理:利用清單文件(Manifest)和快照(Snapshot)機制,實現(xiàn)快速的文件列表和元數(shù)據(jù)操作,極大提升了查詢性能。
- 完整的版本控制:支持時間旅行、回滾和數(shù)據(jù)血緣追蹤。
- 對象存儲(Object Storage):作為數(shù)據(jù)湖的存儲基石,對象存儲提供了近乎無限的擴展性、極高的持久性(通常99.999999999%)和極具競爭力的成本。其按使用量付費的模式,使得存儲海量歷史數(shù)據(jù)的經(jīng)濟性遠勝于傳統(tǒng)塊存儲或HDFS。
二、 方案架構(gòu):數(shù)據(jù)處理與存儲服務(wù)的融合
典型的基于Flink-Iceberg-對象存儲的數(shù)據(jù)湖架構(gòu)通常分為三層:
- 攝入與計算層(Flink):
- 實時攝入:通過Flink SQL或DataStream API,直接從Kafka、MySQL Binlog等數(shù)據(jù)源消費數(shù)據(jù),利用Flink-Iceberg Connector實時寫入Iceberg表。
- 批處理與ETL:對已入湖的數(shù)據(jù),使用Flink Batch模式進行復(fù)雜的清洗、轉(zhuǎn)換、聚合,并將結(jié)果寫回Iceberg表,供上層分析使用。
- 流式分析:構(gòu)建實時數(shù)倉,直接在數(shù)據(jù)湖的流式數(shù)據(jù)上實現(xiàn)實時聚合、關(guān)聯(lián)分析,結(jié)果可實時更新到Iceberg表或?qū)ν馓峁┓?wù)。
- 表格式與元數(shù)據(jù)層(Iceberg):
- 該層是架構(gòu)的“智能大腦”。Iceberg維護著表的結(jié)構(gòu)(Schema)、分區(qū)信息、數(shù)據(jù)文件列表及所有快照歷史。所有對數(shù)據(jù)的讀寫操作都通過Iceberg的接口進行,由其保證事務(wù)性和一致性。元數(shù)據(jù)本身也存儲在對象存儲中,實現(xiàn)了存算分離。
- 持久化存儲層(對象存儲):
- 作為所有數(shù)據(jù)文件(Parquet、ORC、Avro格式)和Iceberg元數(shù)據(jù)文件的最終存放地。對象存儲的廉價、可靠和無限擴展特性,使得數(shù)據(jù)湖可以容納從原始細節(jié)數(shù)據(jù)到高度聚合數(shù)據(jù)的全量數(shù)據(jù),并長期保存。
三、 關(guān)鍵優(yōu)勢:構(gòu)建一體化數(shù)據(jù)服務(wù)
- 統(tǒng)一的批流存儲與服務(wù):Flink處理后的數(shù)據(jù),無論是實時流還是歷史批數(shù)據(jù),都統(tǒng)一寫入Iceberg表。數(shù)據(jù)分析師和數(shù)據(jù)科學(xué)家可以通過同一張Iceberg表,使用Trino/Presto、Spark、Flink自身或Hive等引擎,進行即席查詢、批處理報告或機器學(xué)習(xí)訓(xùn)練,真正實現(xiàn)“一份存儲,多種計算”。
- 卓越的存儲經(jīng)濟性與擴展性:對象存儲的成本效益極高,尤其適合存儲冷溫數(shù)據(jù)。數(shù)據(jù)湖的規(guī)模可以隨業(yè)務(wù)增長平滑擴展,無需預(yù)先規(guī)劃和昂貴的硬件擴容。
- 強大的數(shù)據(jù)治理與可靠性:Iceberg的ACID事務(wù)保障了數(shù)據(jù)質(zhì)量,時間旅行和版本回溯功能便于數(shù)據(jù)審計與故障恢復(fù)。其精細化的元數(shù)據(jù)管理也簡化了數(shù)據(jù)生命周期管理(如過期數(shù)據(jù)清理)。
- 解耦的靈活架構(gòu):存算分離架構(gòu)允許計算資源(Flink集群、查詢引擎集群)根據(jù)負載獨立彈性伸縮,與存儲層互不影響,提升了資源利用率和系統(tǒng)整體彈性。
四、 實踐建議與挑戰(zhàn)
- 實踐建議:
- 小文件治理:流式持續(xù)寫入易產(chǎn)生小文件,需合理配置Flink Checkpoint間隔和Iceberg的提交策略,或定期使用Flink/Spark作業(yè)進行小文件合并(Compaction)。
- 元數(shù)據(jù)優(yōu)化:定期執(zhí)行Iceberg的
expire<em>snapshots和remove</em>orphan_files操作,清理過期元數(shù)據(jù)和數(shù)據(jù)文件,控制成本。
- 查詢加速:對于熱點數(shù)據(jù),可結(jié)合Alluxio等緩存層提升查詢性能;合理設(shè)計Iceberg表的分區(qū)與排序策略,利用數(shù)據(jù)剪枝(Data Skipping)提升查詢效率。
- 潛在挑戰(zhàn):
- 對象存儲的最終一致性模型可能帶來短暫的讀取延遲(但Iceberg通過原子操作在很大程度上規(guī)避了此問題)。
- 跨地域訪問對象存儲可能存在網(wǎng)絡(luò)延遲和成本,需合理規(guī)劃存儲區(qū)域與計算集群的位置。
- 需要一支熟悉Flink、Iceberg和云原生基礎(chǔ)設(shè)施的團隊進行運維和調(diào)優(yōu)。
結(jié)論:
以Apache Flink為動力引擎,Apache Iceberg為組織規(guī)范,對象存儲為堅實基座,所構(gòu)建的現(xiàn)代數(shù)據(jù)湖方案,為企業(yè)提供了兼顧實時性與經(jīng)濟性、統(tǒng)一靈活且易于治理的數(shù)據(jù)處理與存儲服務(wù)平臺。它不僅是技術(shù)棧的升級,更是面向未來數(shù)據(jù)驅(qū)動業(yè)務(wù)的數(shù)據(jù)架構(gòu)范式轉(zhuǎn)變,能夠有效支撐從實時分析、交互查詢到機器學(xué)習(xí)的全場景數(shù)據(jù)應(yīng)用,釋放數(shù)據(jù)資產(chǎn)的深層價值。